Files
Introduction
Anonymizing data or removing any information that makes an individual personally identifiable can be an essential step before sharing data with the public. Anonymization is particularly useful for Police Departments that distribute up-to-date crime information but remove particular information to protect privacy.
This exercise will demonstrate one of the approaches that can be used to anonymize data and will describe a workflow that includes:
- Removing attribute information (e.g. individual names).
- Testing for “block list” words, or words that should be obscured before being released to the public.
- Anonymizing addresses/crime incident locations to display only numbers at the 100-block level.
- Generalizing crime locations using a “block mapping” approach, where incident locations are moved to the midpoint of the street segment on which they occur.
The workflow will write the output to two different files. The first file (Anonymized Output) will be completely anonymized and intended for public use and distribution. The second file (Original Output) will be intended for internal use and maintains all the original attribute information, but moves incident locations to the midpoint of the street segment where they occurred.
Requirements
Before starting this guide, we highly recommend that you have completed at least one of the Getting Started with FME Form articles and familiarize yourself with published parameters.
Step-By-Step Instructions
Before You Begin:
From the Files section of this article, download the Anonymization.zip file. The zip file contains Addresses.gdb, criminal_incident.csv. Roads.dwg, and the complete workflow AnonymizingCrimeData.fmw
1. Open FME Workbench
Open FME Workbench and click on Blank Workspace on the Get Started page.
Alternatively, you can also click on File > New
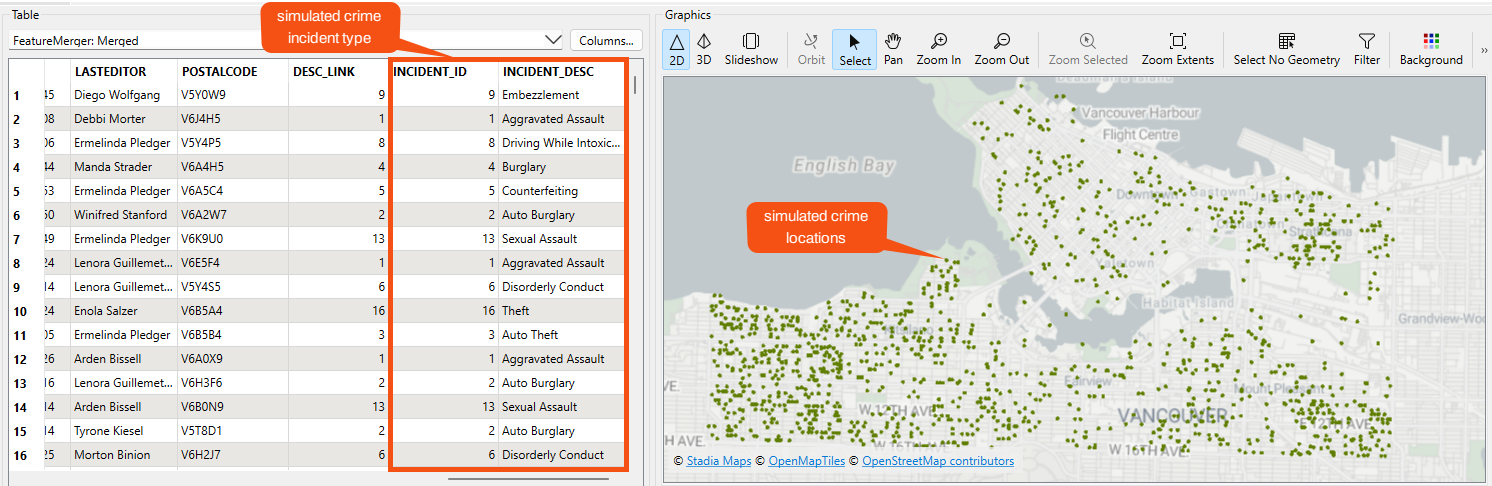
2. Simulate Crime Locations and Incident Type
We will begin our exercise by constructing/simulating a Crime Dataset based on Vancouver postal address information. The next three steps can be omitted if you are already working with a complete Crime Dataset.
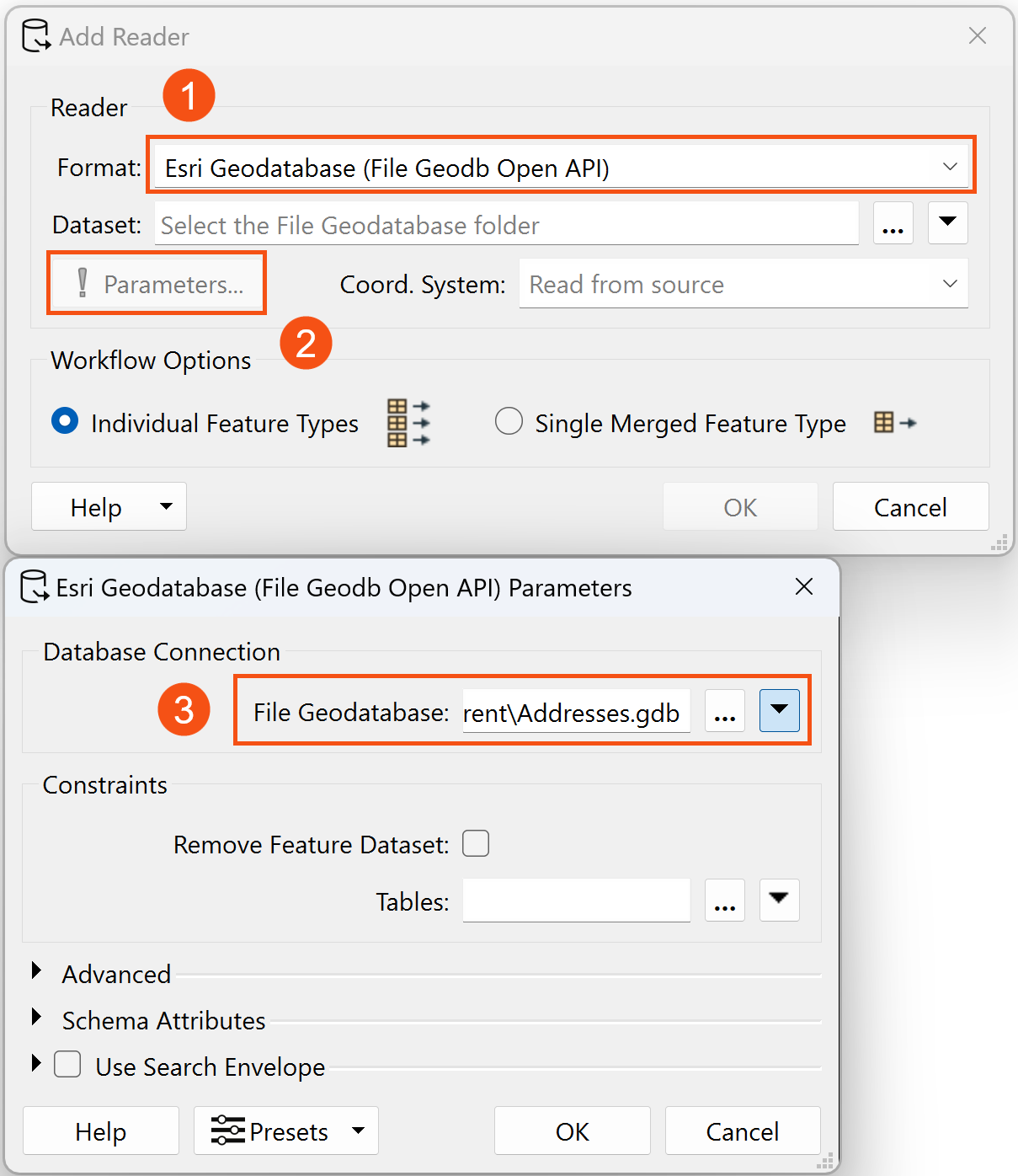
First, add a reader to the canvas, specifying the Esri Geodatabase (File Geodb Open API) as the Format and the “Addresses.gdb” Dataset. Click on the Parameters button, and select “PostalAddress” from the Table List
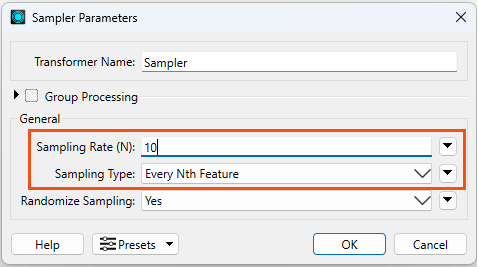
Next, we will use a randomly selected subset of addresses to simulate the locations of crime events in Vancouver. Connect a Sampler transformer to the PostalAddress reader feature type. Set the Sampling Rate (N) to 10 and the Sampling Type to Every Nth Feature. This will randomly select for every 10th address, and discard the remaining addresses.
Now that we have simulated locations for our crimes, we will need to include information for the crime incident type. Add a CSV reader to the canvas, and select the “CRIMINAL_INCIDENT.csv” file. This CSV file will act as our lookup table and contains 17 different crime incident types.
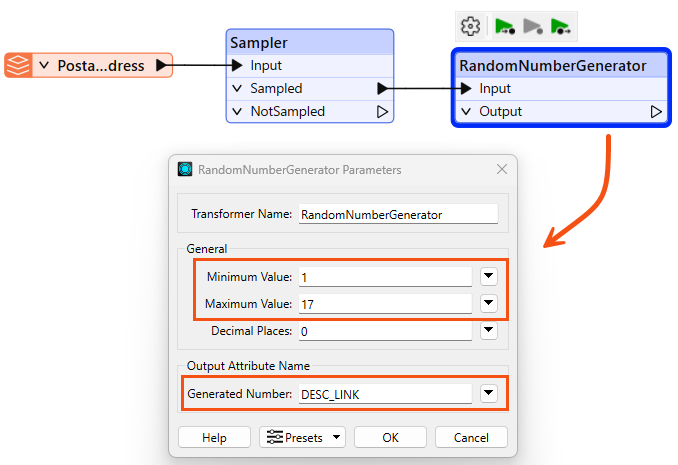
Next, connect a RandomNumberGenerator transformer to the Sampler (Sampled output port) and set the following parameters:
- Minimum Value = 1
- Maximum Value = 17
- Result Attribute: DESC_LINK
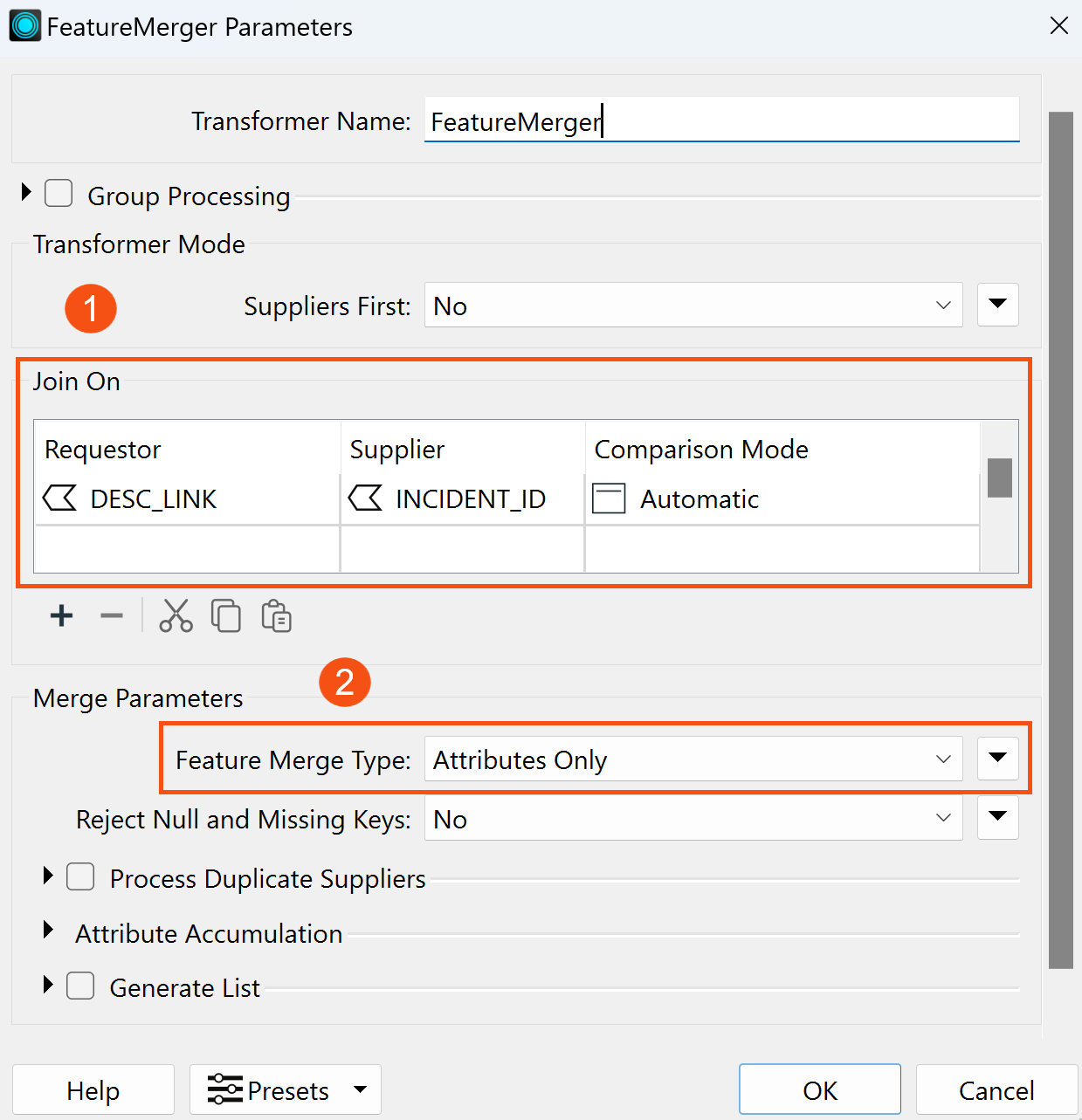
Lastly, add a FeatureMerger transformer and connect its Supplier input port to the CSV reader feature type and its Requestor input port to the RandomNumberGenerator. Set the parameters of the FeatureMerger as:
- Requestor = DESC_LINK
- Supplier = INCIDENT_ID
- Comparison Mode = Automatic
Ensure that the Feature Merge Type is set to Attributes Only. The result will be a randomly selected crime incident type, as defined in the CSV file, appended to the simulated crime locations.
3. Attribute Anonymization
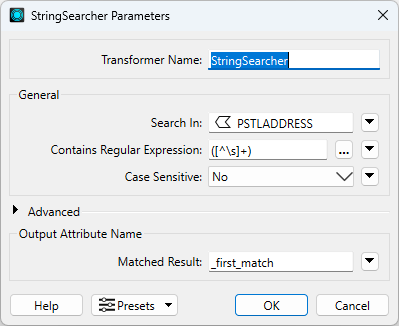
The first step in anonymizing addresses will be extracting the house address from the PSTLADDRESS attribute and writing it to a new attribute _first_match by using a StringSearcher transformer. Connect a StringSearcher to the FeatureMerger Merged output port. Set the StringSearcher parameters:
- Search In: PSTLADDRESS
- Contains Regular Expression: ([^\s]+)
- Matched Result Attribute: _first_match
Next, we will use the AttributeManager to clean up and modify data. For detailed capabilities and step-by-step instructions, refer to the Control Your Data’s Attributes with the AttributeManager Transformer article.
Add an AttributeManager transformer and connect it to the Matched output port of the StringSearcher transformer.
We will remove information that should be kept private, as well as other unnecessary attribute information. In the AttributeManager remove all attributes, keeping only:
- OWNERNM1
- OWNERNM2
- PSTLADDRESS
- PSTLCITY
- INCIDENT_DESC
In addition, create two new attributes:
- Output Attribute = ORIG_PSTLADDRESS, Attribute Value = PSTLADDRESS
- Output Attribute = ORIG_INCIDENT_DESC, Attribute Value = INCIDENT_DESC
Our next step will be to modify “block list” information. For our example, we will replace all assault types (e.g. aggravated assault, simple assault, sexual assault) with “assault” to mask block list words. Set the INCIDENT_DESC parameters in AttributeManager:
- Output Attribute: INCIDENT_DESC
- Attribute Action: Set Value
- Attribute Value: Set in Text Editor
Double-click on the Value section, then click the arrow down button and select "Open Text Editor." Here, we will use FME Feature Attributes and String Functions to change block list words. For a comprehensive list of functionalities, refer to the String Functions documentation.
In the Text Editor, under String Functions, select ReplaceRegularExpression. Once selected, the expression will appear in the Text Editor area. You will need to change all the words in red for the expression to run successfully.
Current expression:
@ReplaceRegularExpression(<string>,<regExp>,<after>,caseSensitive=TRUE)
Modified expression:
@ReplaceRegularExpression(@Value(INCIDENT_DESC),Aggravated Assault|Sexual Assault|Simple Assault,Assault,caseSensitive=FALSE)
Now, we will use a conditional statement to set attribute values. Conditional statements are used to first test for the length of the address, then replace trailing numbers with 0’s, and then write this value to an attribute named Address_Anon. First, create a new attribute in the AttributeManager:
- Output Attribute: Address_Anon
- Attribute Action: Set Value
- Attribute Value: Set in Conditional Value
Double-click on the Value section, then click the arrow down button and select "Conditional Value." Complete the Conditional Statements as below:
| Left Value | Operator | Right Value | Value | |
| If | @StringLengh(@Value(_first_match)) | = | 4 | @Left(@Value(_first_match),2)00 |
| Else If | @StringLengh(@Value(_first_match)) | = | 3 | @Left(@Value(_first_match),1)00 |
| Else If | @StringLengh(@Value(_first_match)) | = | 2 | 0 |
| Else If | @StringLengh(@Value(_first_match)) | = | 1 | 0 |
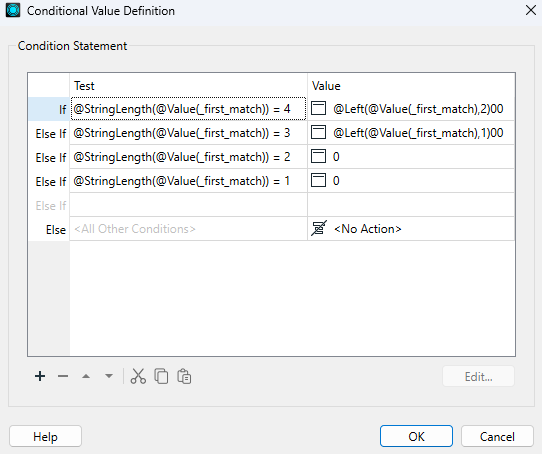
The conditional statements systematically check the length of the numeric part of the address and modify it to a generalized format by replacing the trailing numbers with zeros. This method ensures that:
- Addresses with 4 digits retain the first 2 digits.
- Addresses with 3 digits retain the first digit.
- Addresses with 2 or fewer digits are completely anonymized to "0".
This helps in maintaining a consistent anonymization strategy that can be uniformly applied, ensuring privacy. Refer to the Testing If-Then Conditional Statements article for more examples and exercises.
Lastly, we will update the original address location with information generalized at the block level by using a ReplaceString expression. Set the PSTLADDRESS parameters in AttributeManager:
- Output Attribute: PSTLADDRESS
- Attribute Action: Set Value
- Attribute Value: Set in Text Editor
Double-click on the Value section, then click the arrow down button and select "Open Text Editor." In the Text Editor, under String Functions, select ReplaceString. Once selected, the expression will appear in the Text Editor area. You will need to change all the words in red for the expression to run successfully. Full list of functionalities can be found in String Functions documentation.
Current expression:
@ReplaceString(<string>,<before>,<after>,caseSensitive=TRUE)
Modified expression:
@ReplaceString(@Value(PSTLADDRESS),@Value(_first_match),@Value(Address_Anon),caseSensitive=FALSE)
This process will overwrite the original address values with 100-block level addresses. Ensure your Attribute Actions are arranged in the correct order, as shown in the image below. Attribute actions are executed sequentially, so matching the order in the image is important. If any action appears in red, the order is incorrect and the transformer will not run.
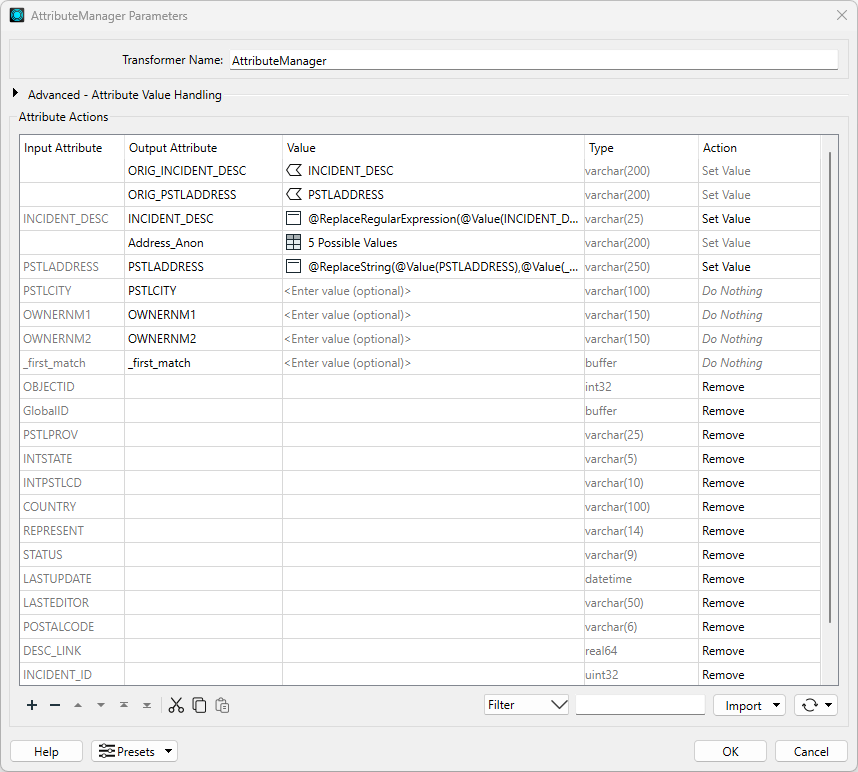
Your workspace now should look similar to the below image.
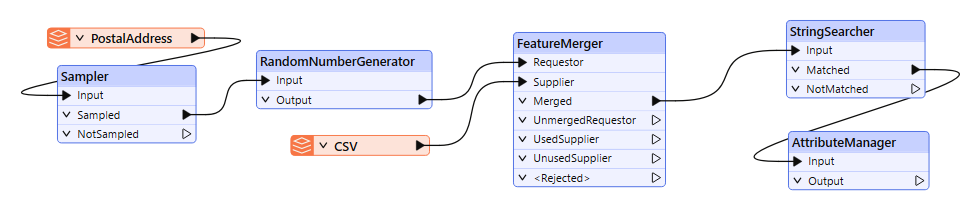
4. Plot Incident Locations to the Midpoint of the Street Segments
We can now use our updated address information to reference incident locations to road segments and move crime locations to the midpoint of the street segments.
Add an AutoCAD DWG/DXF reader to the canvas, and select the Roads dataset. Open its parameters, and set Group entities by Attribute Schema. Before adding the reader, make sure to set the Workflow Option to Single Merged Feature Type. A new Roads feature type named <All> will be added to the canvas.
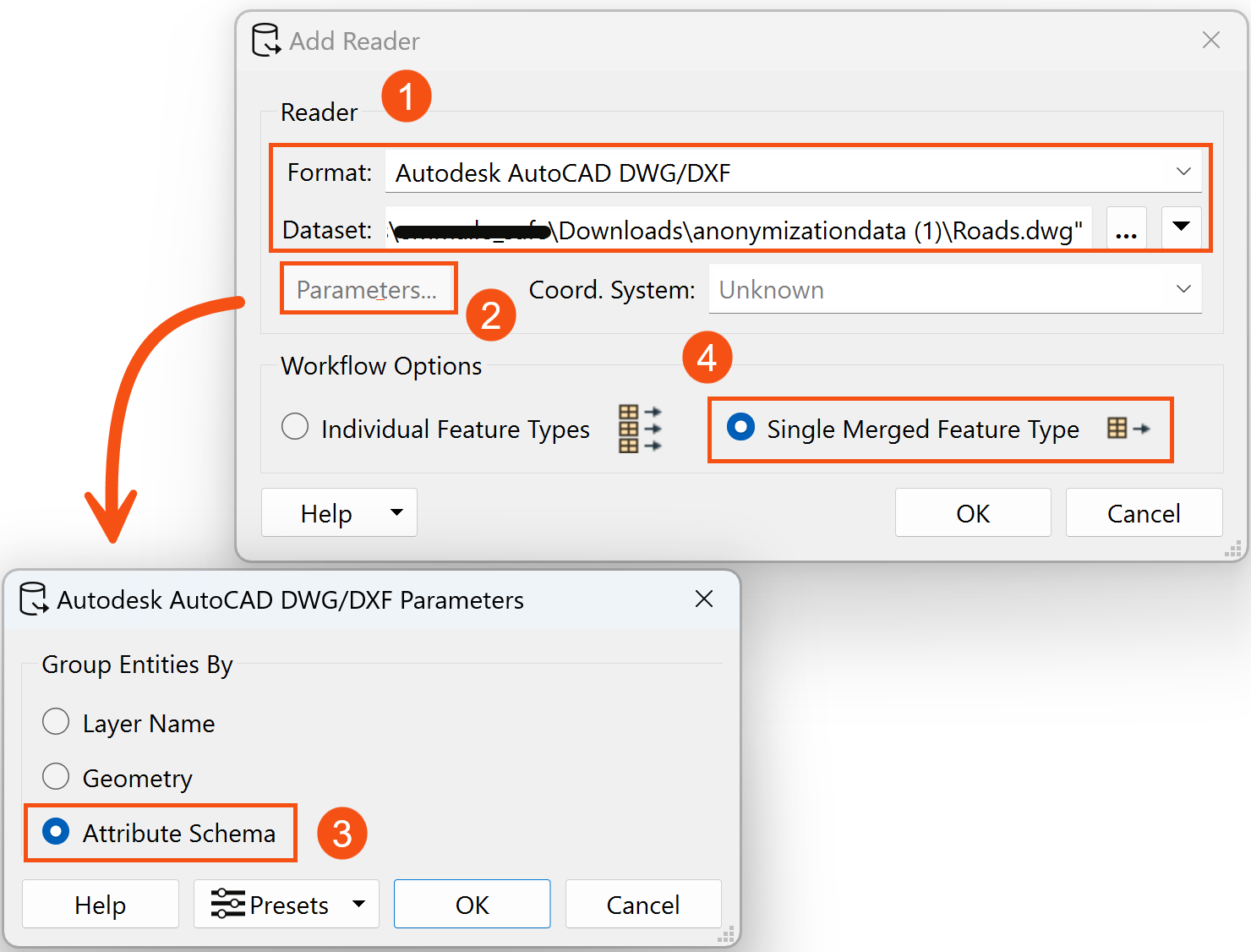
Some of the roads in Vancouver do not have single 100-block addresses but instead, make use of a range of addresses that share the same road segment (e.g.) ‘1300-1400 Laburnum St’. Before we can match our crime incidents to street segments, we must create road segments for each 100-block (e.g.) ‘1300 Laburnum St’, and ‘1400 Laburnum St’. We will make use of StringSearcher and StringReplacer transformers to modify the address information on road segments in order to match addresses.
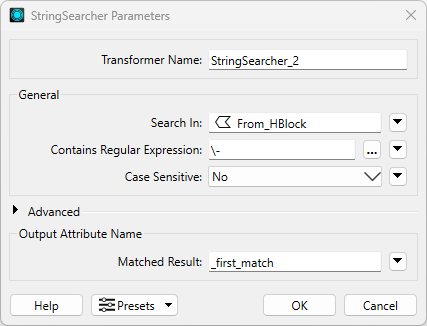
Connect a StringSearcher transformer to the <All> (roads) reader feature type. Open its parameters and set:
- Search In: From_HBlock
- Contains Regular Expression: \-
- Case Sensitive: No
- Matched Result: _first_match
Add two StringReplacers and connect them both to the Matched output port of the StringSearcher_2.
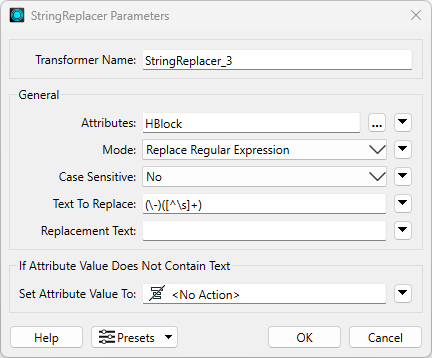
The first StringReplacer transformer will be used to keep the first address in the range, discard the second address, and append this information to the road segment. Set the parameters of the first StringReplacer transformer:
- Attributes: HBlock
- Mode: Replace Regular Expression
- Case Sensitive: No
- Text to Replace: (\-)([^\s]+)
- Set Attribute Value To: <No Action>
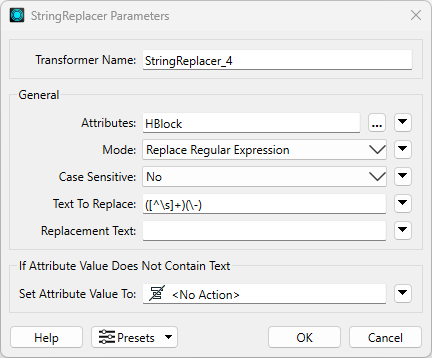
The second StringReplacer will be used to keep the second address in the range, discard the first address, and append this information to the road segment. Set the parameters of the second StringReplacer transformer:
- Attributes: HBlock
- Mode: Replace Regular Expression
- Case Sensitive: No
- Text to Replace: ([^\s]+)(\-)
- Set Attribute Value To: <No Action>
Your workspace now should look similar to the below image.
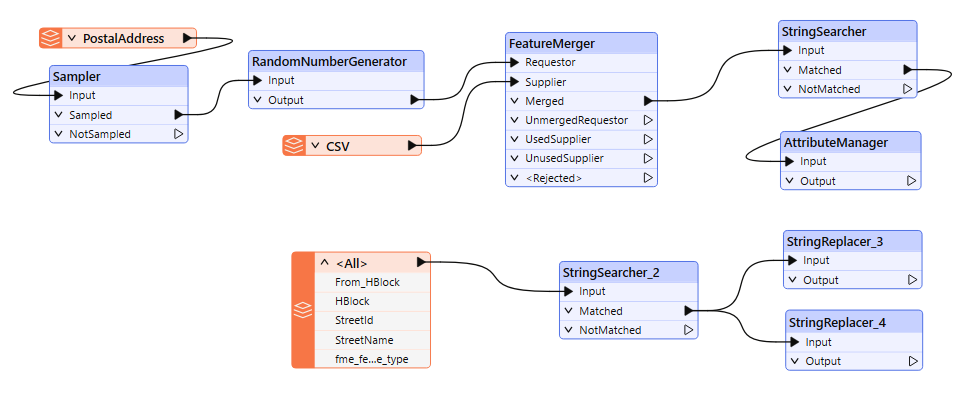
5. Create Block Mid-Points
Add another FeatureMerger transformer and connect its Requestor input port to the AttributeManager transformer output port. Connect the FeatureMerger’s Supplier port to the both the StringReplacer transformers, and the StringSearcher_2 NotMatched output port. The FeatureMerger connections should appear as below:
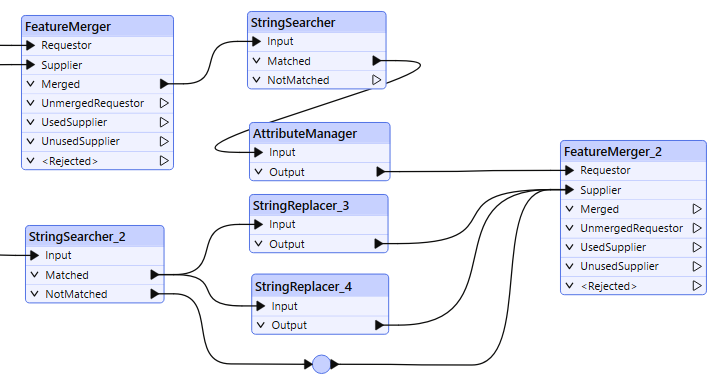
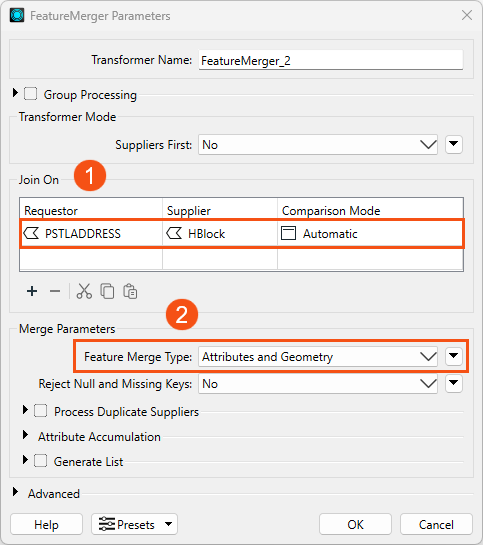
Open the FeatureMerger transformer parameters and set the Join On to:
- Requestor: PSTLADDRESS
- Supplier: HBlock
- Comparison Mode: Automatic
-
Merge Parameters:
- Feature Merge Type: Attributes and Geometry
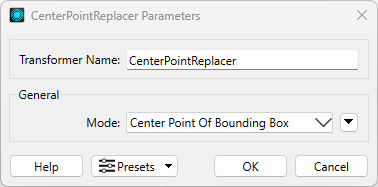
Add a CenterPointReplacer transformer to the canvas and connect it to the FeatureMerger Merged output port. In the parameters, set the Mode to Center Point Of Bounding Box. This will create a new center point for each road segment where a crime incident has taken place.
6. Writing the Output
The final steps will involve branching our workspace so that two files are created, one for public use that contains anonymized data, and one is for internal use that includes all the original attribute information.
Internal Use (Original Data):
Add a generic writer to the canvas using the default setting.
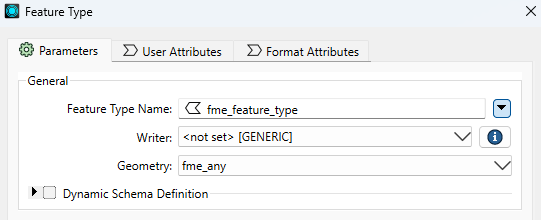
When the Feature Type window pops up, change the Feature Type Name to fme_feature_type attribute value. This method is called Feature Type Fanout, which is a way to split output data based on the value of an attribute. To learn more about Feature Type Fanout, see the Fanout | How to Separate Features Based on an Attribute article. Additionally, set the Geometry to fme_any.
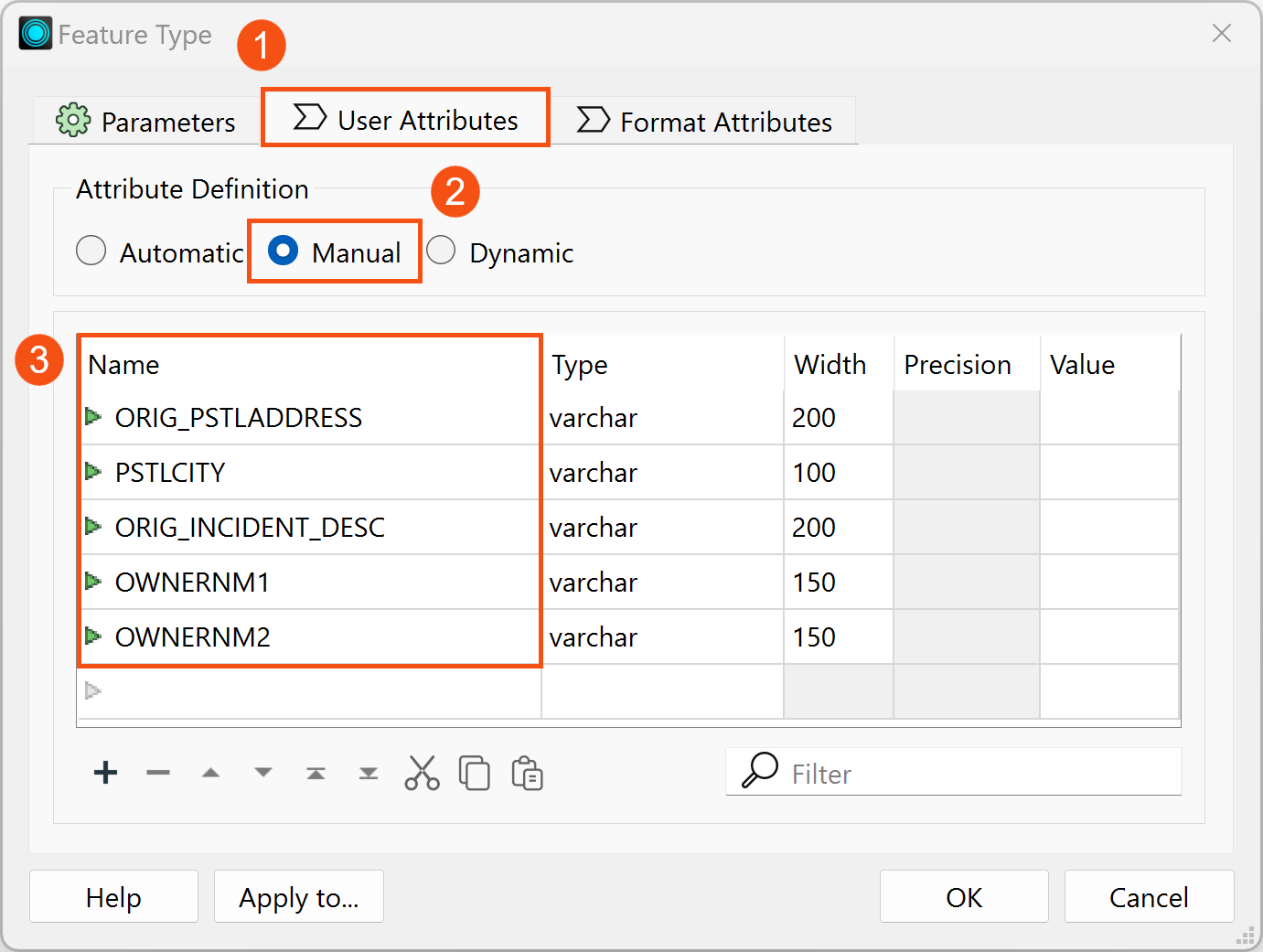
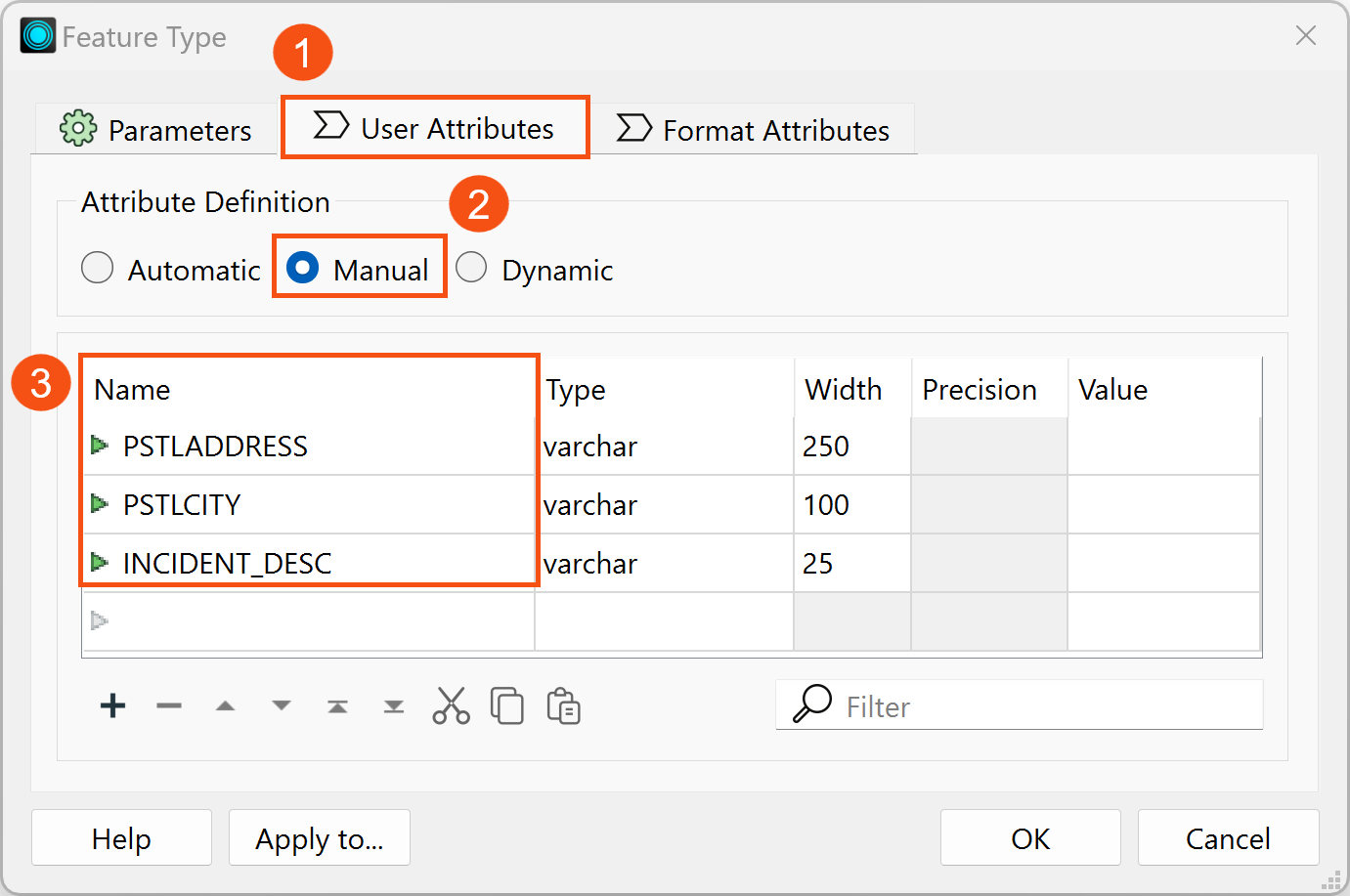
Once the parameters are set, close the window and connect the Point output port from the CenterPointReplacer transformer to the generic writer. Double-click on the writer to open the Feature Type window again, then select the User Attributes tab next to the Parameters tab. Under Attribute Definition, switch from Automatic to Manual. This allows you to modify all attributes. Delete everything except the following attributes:
- ORIG_PSTLADDRESS
- PSTLCITY
- ORIG_INCIDENT_DESC
- OWNERNM1
- OWNERNM2
Since this file will be for internal use, you can keep all the necessary original attributes.
External Use (Anonymized Data):
Add another generic writer to the canvas and repeat the previous steps up to the User Attributes tab. To maintain data anonymization, keep only the attributes that have already been altered:
- PSTLADDRESS
- PSTLCITY
- INCIDENT_DESC
7. Create and Adjust User Attributes
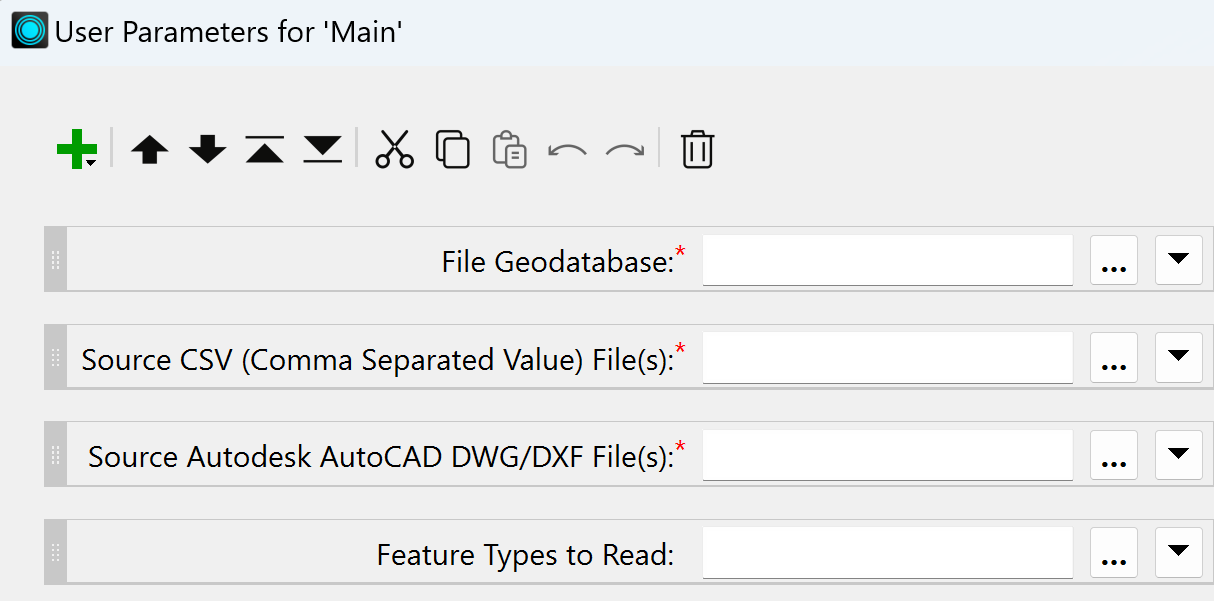
On the Navigator window on the left, right-click on User Parameters and choose Manage User Parameters. Delete all user attributes except the following four:
Now, you will create two group boxes to separate the original and anonymized outputs. Click on the green “+” sign button and choose the Group Box option. Adjust the parameters to the following:
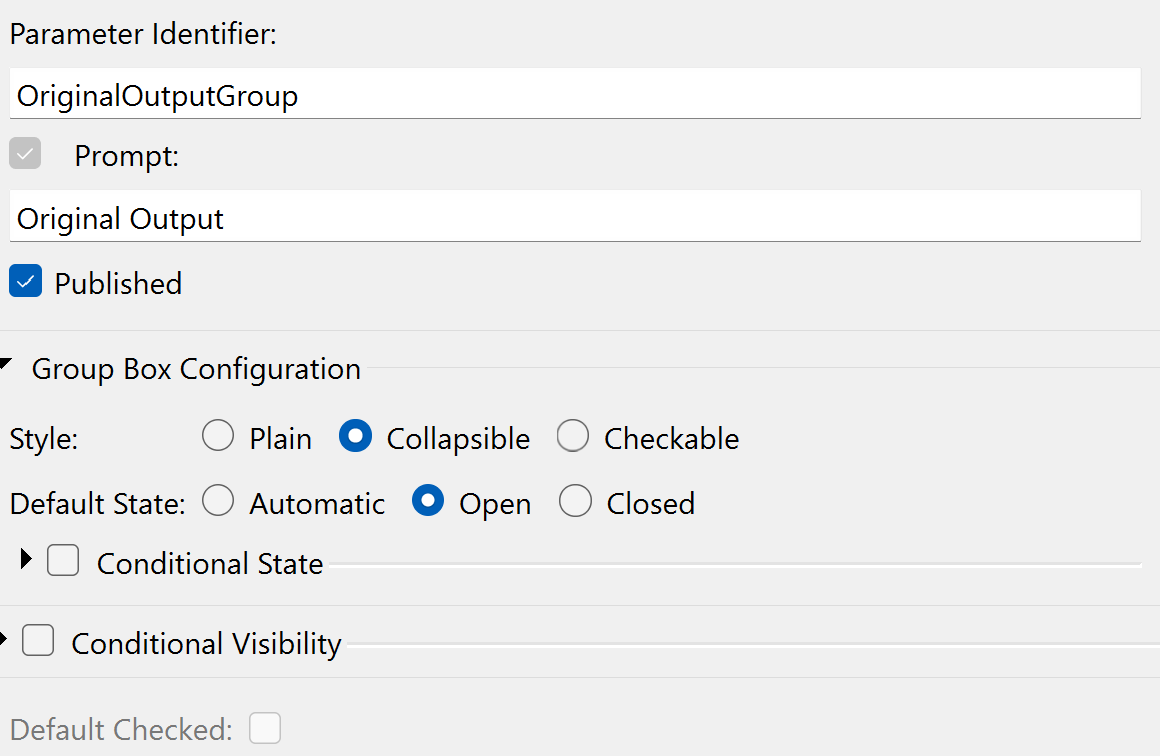
- Parameter Identifier: OriginalOutputGroup
- Prompt: Original Output
- Published: Yes
-
Group Box Configuration
- Style: Collapsible
- Default State: Open
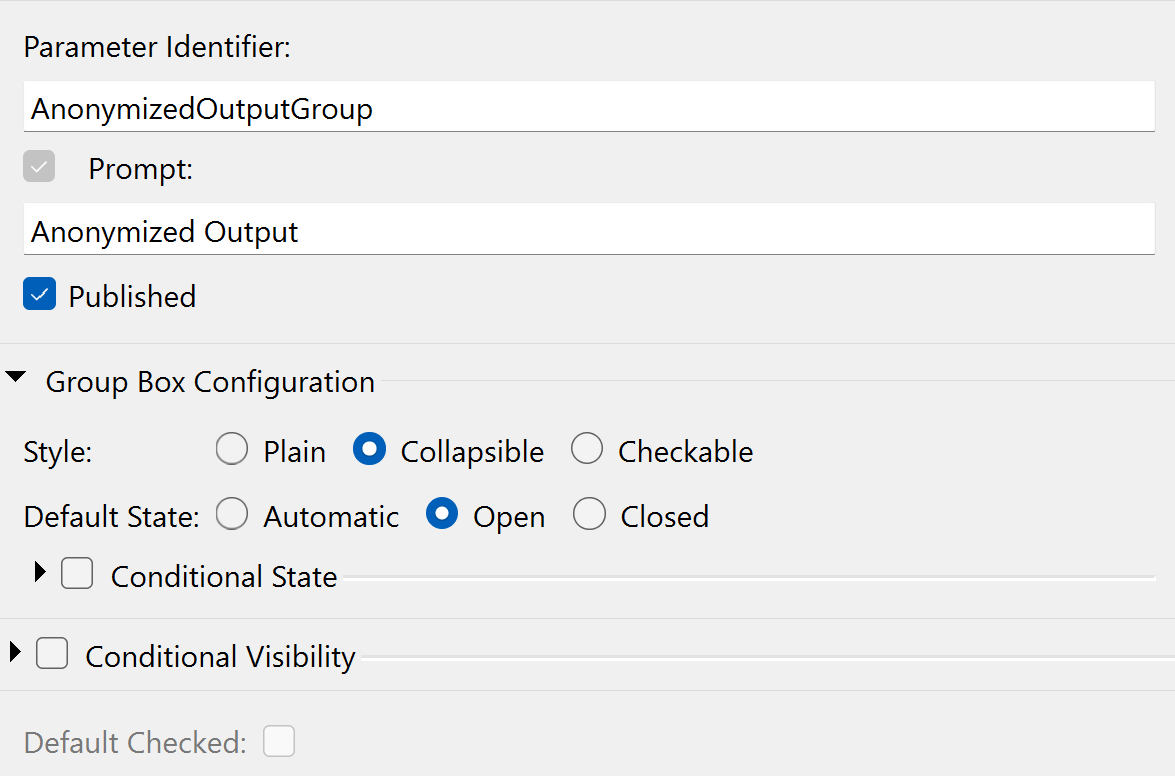
Add another Group Box and keep the same parameters as the first Group Box except for the Parameter Identifier and Prompt:
- Parameter Identifier: AnonymizedOutputGroup
- Prompt: Anonymized Output
- Published: Yes
-
Group Box Configuration
- Style: Collapsible
- Default State: Open
In each of these group boxes, you will add three more user parameters.
Original Output Group Box:
- Output Format parameter:
-
- Type: Choice
- Parameter Identifier: OriginalOutput
- Prompt: Output Format
- Parameter: Published, Required
-
Choice Configuration: Dropdown
- Choices: CSV, XLSXW, SHAPEFILE, FILEGDB, GEOJSON - You can use Import from Writer to quickly search for them.
- Allow Choice Edit: No
- Default Value: <Leave Blank>
- File Name parameter:
-
- Type: Text
- Parameter Identifier: OriginalFileName
- Prompt: File Name
- Parameter: Published
- Editor Syntax: Plain Text (Uniline)
- Default Value: Original_Output
- Output Coordinate System parameter:
-
- Type: Choice
- Parameter Identifier: COORDS_ORIGINAL
- Prompt: Output Coordinate System
- Parameter: Published
-
Choice Configuration: Dropdown
- Choices: BCALB-83, BCPOLY-83, UTM83-10, EPSG: 4326 - You can use Import from Coordinate Systems to quickly search for them.
- Allow Choice Edit: No
- Default Value: <Leave Blank>
Anonymized Output Group Box:
- Output Format parameter:
-
- Type: Choice
- Parameter Identifier: AnonOutput
- Prompt: Output Format
- Parameter: Published, Required
-
Choice Configuration: Dropdown
- Choices: CSV, XLSXW, SHAPEFILE, FILEGDB, GEOJSON - You can use Import from Writer to quickly search for them.
- Allow Choice Edit: No
- Default Value: <Leave Blank>
- File Name parameter:
-
- Type: Text
- Parameter Identifier: AnonFileName
- Prompt: File Name
- Parameter: Published
- Editor Syntax: Plain Text (Uniline)
- Default Value: Anonymized_Output
- Output Coordinate System parameter:
-
- Type: Choice
- Parameter Identifier: COORDS_ANON
- Prompt: Output Coordinate System
- Parameter: Published
-
Choice Configuration: Dropdown
- Choices: BCALB-83, BCPOLY-83, UTM83-10, EPSG: 4326 - You can use Import from Coordinate Systems to quickly search for them.
- Allow Choice Edit: No
- Default Value: <Leave Blank>
By this step, your Parameter Manager window should look similar to this:
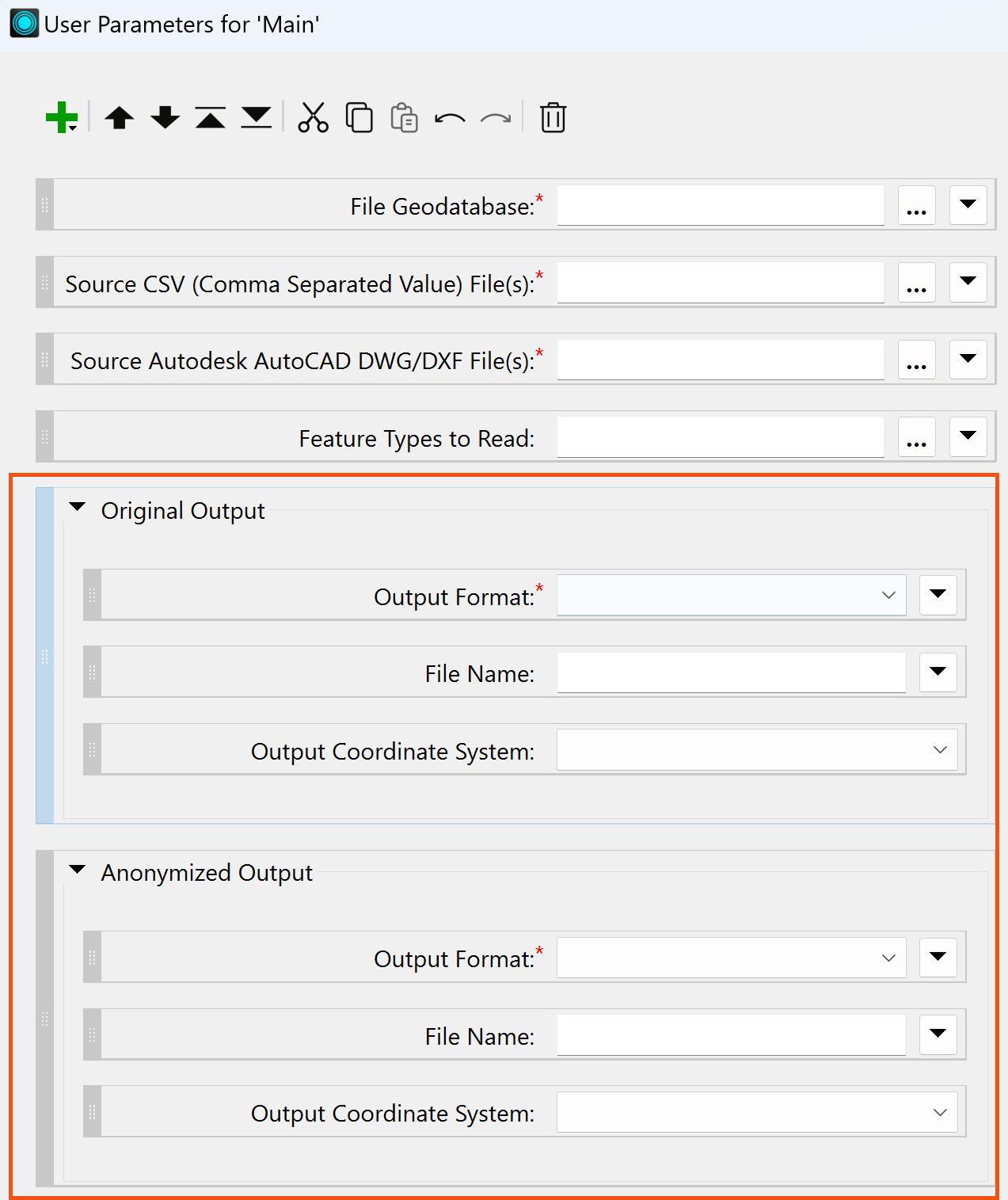
8. Link to a Parameter
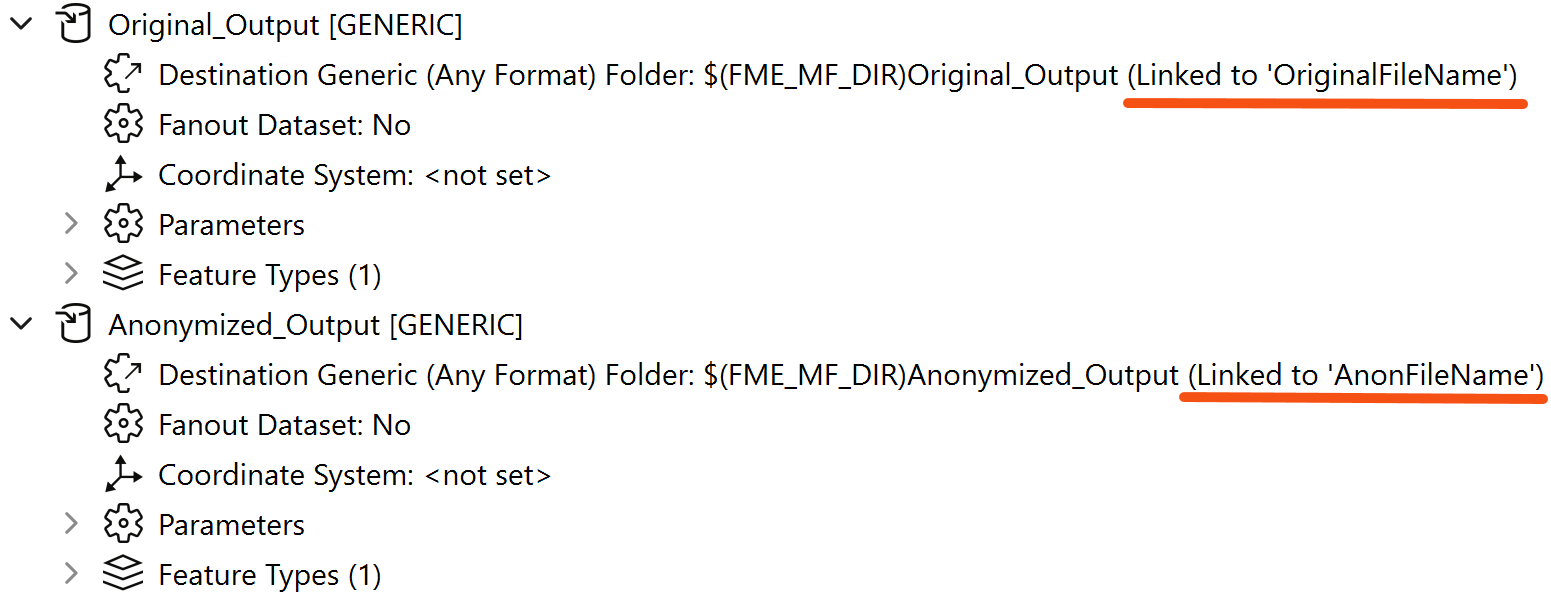
In the Navigator window, ensure that the Original_Output and Anonymized_Output writers are linked to their respective user parameters. This will create two separate folders for the output files when the workspace runs, enhancing ease of accessibility.
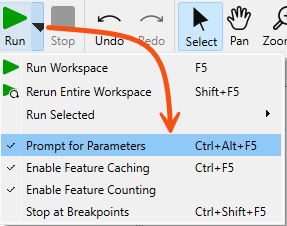
9. Test Workspace
Test out your workspace to ensure that it works by running the Workspace with Prompt. Click on the drop-down arrow next to the Run button and enable Prompt for Parameters.
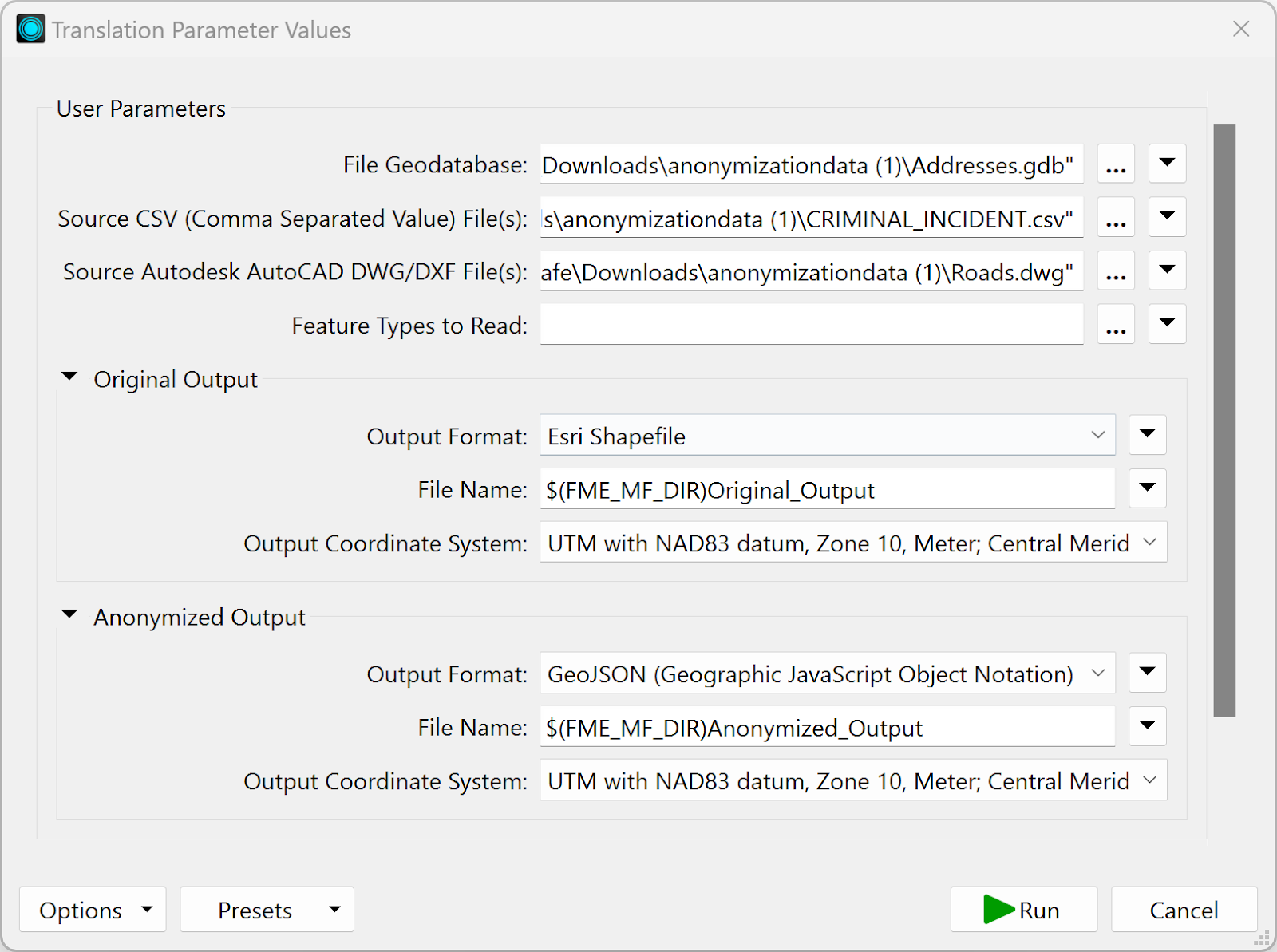
Then click the Run Workspace button. You will be prompted to enter values for the parameters. The first three parameters should already be filled out, as we set them up when adding the readers in previous steps. By utilizing the Group Box option in Parameter Manager, the parameters are now clearly labeled. Users can select their desired output format from the curated list we set up earlier.
Once ready, click Run.
Your workspace should look similar to this now. Feel free to add your own bookmarks and annotations to help you understand the steps better. You can refer to the Organizing Workspaces documentation to efficiently arrange your workspace.
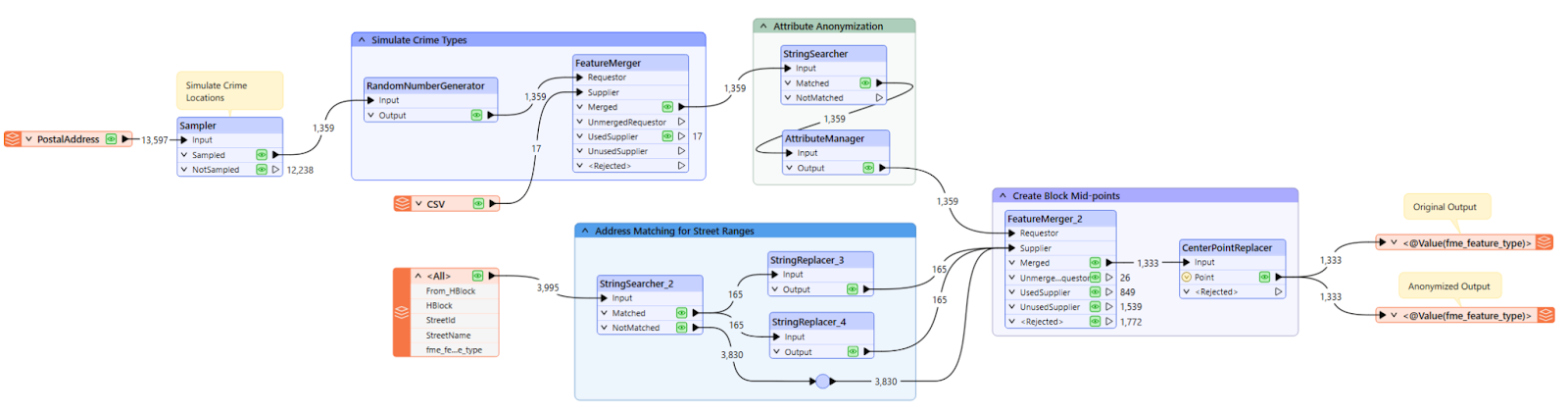
Once the workspace finished running, check the Translation Log for any errors and check the destination folder to make sure you have the data translated correctly.
Congratulations, you have completed building a workspace for Crime Data Anonymization! Explore our FME Support Center for more tutorials, tips, and guidelines. Additionally, visit FME Academy to explore our comprehensive training catalog for a more in-depth study!